Хранимые и вычисляемые данные
 3 мин.
3 мин. 
Состоянием приложения являются данные, сохраняемые в памяти на определённом этапе его работы. Очень важно понимать, что не любые данные и не в любой ситуации имеет смысл куда-либо сохранять.
«Плохие программисты думают о коде. Хорошие программисты думают о структурах данных и их взаимосвязях»
— Линус Торвальдс, создатель Linux.
 Хранимые данные
Хранимые данные
Представьте себе компонент, отображающий некий список с возможностью фильтрации.
Я неоднократно встречал реализации подобных компонентов, предполагающие сохранение отфильтрованного списка в состоянии.
import { useEffect, useMemo, useState } from "react";
function filterByType(items, types) { // TODO: Механизм фильтрации}
const FilterableList = ({ items }) => { const [selectedTypes, setSelectedTypes] = useState([]); const [filteredItems, setFilteredItems] = useState(items);
/** Обработчик изменения параметров фильтрации */ const handleTypesChange = (types) => { // Сохраняем новое значение фильтра setSelectedTypes(types); // Применяем фильтр к списку setFilteredItems((items) => filterByType(items, types)); };
return ( <div> <TypeSelector value={selectedTypes} onChange={handleTypesChange} />
<List items={filteredItems} /> </div> );}; При такой реализации мы получаем два состояния, которые на уровне кода не имеют никакой связи между собой.

Значения, которые мы явным образом сохраняем в некоторое состояние, называются хранимыми (stored).
Но с концептуальной точки зрения данные в таком случае имеют взаимосвязи, а именно: результаты фильтрации напрямую зависят от исходного списка и параметров фильтрации. Если код не отражает эту идею и данные хранятся обособленно, то мы можем, например, в какой-то момент при изменении одного из значений забыть изменить второе, и состояние перестанет быть
const FilterableList = ({ items }) => { const [selectedTypes, setSelectedTypes] = useState([]); const [filteredItems, setFilteredItems] = useState(items);
const handleTypesChange = (types) => { // Сохраняем новое значение фильтра setSelectedTypes(types); // Забыли отфильтровать список!!! };
return ( <div> <TypeSelector value={selectedTypes} onChange={handleTypesChange} />
<List items={filteredItems} /> </div> );}; Такой подход может быть актуальным при проектировании больших распределённых систем (
Вычисляемые данные
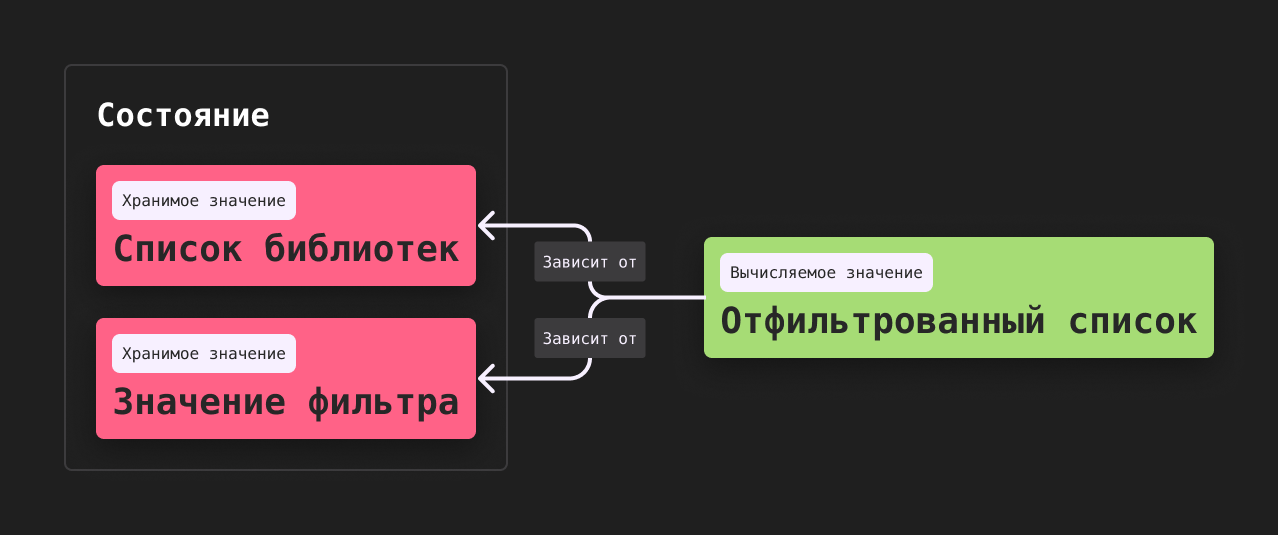
Значения, которые мы можем вычислить на основе уже имеющихся данных, называются, как вы можете догадаться, вычисляемыми (computed/derived).
С помощью вычисления «на лету» мы избавляемся от одного совершенно ненужного состояния.
const FilterableList = ({ items }) => { const [selectedTypes, setSelectedTypes] = useState([]);
const filteredItems = filterByType(items, selectedTypes);
return ( <div> <TypeSelector value={selectedTypes} onChange={setSelectedTypes} />
<List items={filteredItems} /> </div> );}; Оптимизация вычисляемых данных
В процессе отладки может выясниться, что функция фильтрации достаточно ресурсоёмкая и выполнение её в каждом рендере будет неэффективным, появится соблазн всё-таки сохранять результаты её выполнения в состояние из соображений оптимизации.
const FilterableList = ({ items }) => { const [selectedTypes, setSelectedTypes] = useState([]); const [filteredItems, setFilteredItems] = useState(items);
useEffect(() => { setFilteredItems((items) => filterByType(items, types)); }, [items, selectedTypes]);
return ( <div> <TypeSelector value={selectedTypes} onChange={setSelectedTypes} />
<List items={filteredItems} /> </div> );}; Такие рассуждения имеют смысл, но ввиду явного наличия дополнительного состояния код становится гораздо менее декларативным и не в полной мере отражает суть решаемой задачи.
На самом деле задача оптимизации в данном случае может быть решена с помощью мемоизации вычислений.
const FilterableList = ({ items }) => { const [selectedTypes, setSelectedTypes] = useState([]);
const filteredItems = useMemo( () => filterByType(items, selectedTypes), [items, selectedTypes] );
return ( <div> <TypeSelector value={selectedTypes} onChange={setSelectedTypes} />
<List items={filteredItems} /> </div> );}; Чисто технически мемоизация тоже создаст некоторое состояние для компонента, но это состояние инкапсулировано внутри функции мемоизации и мы не можем влиять на него напрямую, за счёт чего код гораздо лучше отражает суть задачи и не позволяет нам сделать лишних действий.
Зависимости React-хуков
При проектировании состояния без анализа его концептуальной структуры также можно столкнуться с необходимостью проигнорировать правила для React-хуков, которые
Заключение
Проектировать состояние приложения стоит таким образом, чтобы хранимым был согласованный набор данных, необходимый и достаточный для работы приложения, а все остальные данные, которые делают этот набор избыточным, стоит вычислять «на лету», при необходимости добавляя кеш или мемоизацию.